Handling exceptions
Java나 c# 프로그래밍을 해 보신 분이라면 익숙한 방법이라 생각됩니다.
2005에서는 에러 처리 부분을 try catch 구문을 통해 처리할 수 있도록 지원합니다.
Error handling function
Catch 절 안에서 사용할 수 있는 함수들입니다.
- ERROR_NUMBER() : 에러 번호
- ERROR_SEVERITY() : severity (?)
- ERROR_STATE() : 상태 번호
- ERROR_MESSAGE() : 에서 메시지
- XACT_STATE() : 트랜잭션의 상태 (return 1, 0, -1)
Common table expressions (CTE)
새로 추가 된 TSQL 구문 중 꽤나 강력한 구문이 아닌가 싶네요.
- CTE is temporary named resultset. CTE는 임시로 명명된 결과셋이다.
- CTE는 저도 많이 다뤄 보지 않아 뭐라고 딱 설명드리긴 좀 어려운 부분이 있지만, 재귀 쿼리를 가능하게 해 주는 문법입니다. 물론 재귀 쿼리 외에도 사용은 가능하지만…
- 자세한 내용은 다른 자료를 참고사시고..
Pivot
제일 처음 피봇이라는 용어를 들은게 농구에서가 아니었나 싶은데요.^^’’ 맞나??
피봇에 대한 설명은 말 보다는 테이블 예를 하나 보는게 가장 좋을 듯 싶네요.
행으로 되어 있는 레코드를 열로 바꿔 준다고 말하면 될지…
1 | swish |
2 | attachit |
3 | swish |
4 | swish |
1 | color | blue |
1 | type | oil |
1 | amount | 1 gal |
2 | pitch | 12-3 |
2 | diameter | .25 in |
위 두 테이블을 아래와 같이 쿼리 하고 싶은 경우 사용할 수 있습니다.
| | amount | type | color |
1 | swish | 1 gal | oil | blue |
3 | swish | 1 qt | latex | red |
SELECT * FROM properties
PIVOT(
MAX(value)
FOR name IN ([color], [type], [amount]))
AS P WHERE id IN ( SELECT id FROM products WHERE name = ‘swish’)
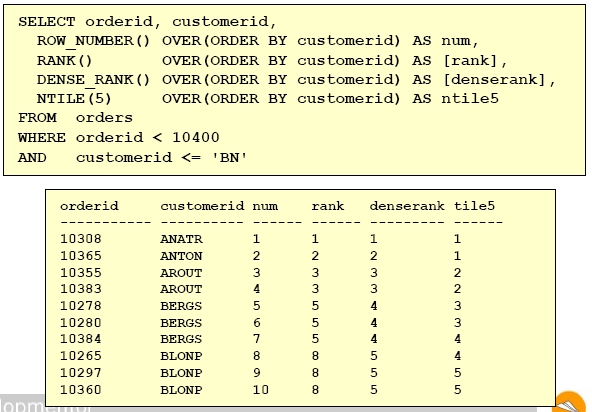
Ranking and Windowing Functions
가뭄에 단비와 같은 함수들이 아닌가 싶네요… 이건 정말로 백문이 불여일견입니다.
예를 보시죠~
- ROW_NUMBER : identity 값이라고 보시면 되고요. 일렬번호를 붙인 거죠
- RANK : 이건 순위를 매긴 건데… 같은 등수가 있으면 다음 등수는 skip합니다.
- DENSE_RANK: 역시 순위를 매기는데 같은 등수가 여러명 있어도 다음 등수는 그대로
- NTILE(n) : 이건 전체를 n등분 하겠다는 거죠.
아주 유용한 함수들이 아닌가 싶습니다. 특히 ranking을 자주 매기는 사이트에선..
Windowing
이것 역시 판타스틱한 기능이 아닌가 싶네요 ^^’’
특정 컬럼을 기준으로 분할해서 랭킹을 매깁니다.
예를 들어 지역별 랭킹, 나이대별 랭킹 등…
Cross apply
Inner join과 동일
그냥 사용하면 일반적인 inner join과 동일하지만 UDF와 함께 사용할 경우 좋은 성능을 발휘한다.
Outer Apply
Left outer join과 동일
Apply와 동일하게 UDF와 함께 사용할 때 좋은 성능 발휘
아래의 세개의 구문 중 위 두개는 동일한 결과를 나타내고 맨 아래 쿼리는 보다 적은 필터링의 일반적인 쿼리이다.
SELECT * FROM invoice CORSS APPPLY greater(amount, 1500)
SELECT T1.*, T2.amount v
FROM invoice T1
JOIN invoice T2 ON T1.amount > 1500 AND T1.id = T2.id
SELECT * FROM invoice WHERE amount>1500
이 세 개의 쿼리의 실행계획을 살펴보면 beta1에선 각각 (30%, 40%, 30%)의 성능 비교가 됐고, beta2에선 각각 (22%. 57%. 21%)의 성능 비교가 됐다. 절대적 이진 않지만 UDF와 CROSS APPLY를 사용한 경우의 성능이 T-SQL의 join을 사용할 때보다 성능이 좋았다.
이 차이는 beta3, RTM이 나오면서 바뀔 수도 있다고 하니 참고바람.
TOP Query
드디어 TOP 뒤에 변수가 들어오거나 일반적인 쿼리를 넣을 수도 있게 됐다.
DECLARE @top as int
SET @top = 10
SELECT TOP @top * FROM authors
시간이 없어 이 정도로 정리..