2단계 커밋 프로토콜...
얘기는 많이 나오는데 자세히 모르는 분들이 많을 것 같다.
컴퓨터 공학을 전공했다면, 물론 수업시간에 배웠을 내용이겠지만...
쓸만한 자료가 있어서 퍼 왔다.
-------------------------------------
The Two-Phase Commit Protocol
The Two-Phase Commit (2PC) protocol is a simple and elegant ACP with two types of processes: A single coordinator that decides whether to reach a global commit or abort decision, and the participants that execute the transaction's resource accesses and vote whether to commit or abort. The commit decision is made according to the global commit rule [11]:
- -
- If even one participant votes to abort the transaction, the coordinator has to reach a global abort decision.
- -
- If all participants vote to commit the transaction, the coordinator has to reach a global commit decision.
A description of 2PC that does not consider failures is provided in this section. Failure scenarios and a recovery protocol is described in section 2.6.2. Figure 2 should be helpful: The circles represent states, the whole lines represent state changes, the dashed lines represent messages (labeled with the message types), and the rectangles represent logging actions.
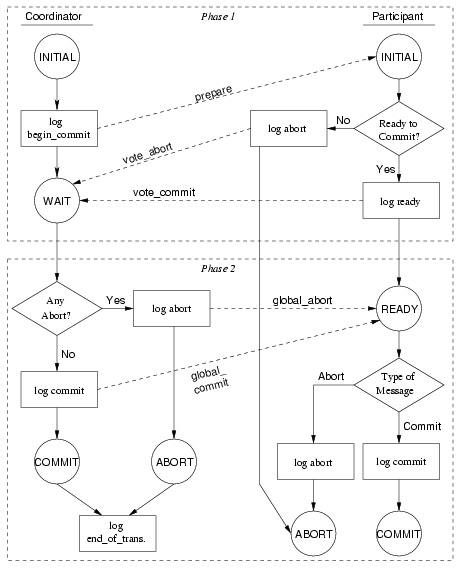
- The coordinator fails in the initial state: The coordinator must simply be restarted and reinitialized.
- The coordinator fails after the begin commit record is written to the log but before the prepare command is sent: On recovery, the coordinator knows from the log that the commit process is started, but it does not know whether the prepare command has been sent, so it must be (re)transmitted. Note that this may cause duplicate messages. We will explain later how this protocol can be implemented in a manner that makes duplicate messages harmless.
- The coordinator fails while in the wait state: If there are votes on the channel, it must have sent the prepare command, so it can reenter the wait state. If not, the coordinator does not know if it has sent the prepare command, so it is (re)transmitted.
- The coordinator fails after logging its final decision, but before informing the participants of the decision: The decision has been recorded on the log, so it only needs to transmit it to the participants.
- The coordinator fails in the commit or abort states: The decision is already logged and broadcast, so it only needs to write an end of transaction record in the log.
Then the failures and recovery for the participant:
- The participant fails in the initial state: The participant will automatically be restarted when the system is restarted, and it will find the prepare message on the channel.
- The participant fails after writing the abort record in the log but before sending vote_abort: Simply retransmit the vote_abort message.
- The participant fails in the ready state: If there is a global_commit or global_abort message on the channel, act on it. Otherwise, (re)transmit the vote_commit message.
- The participant fails while writing the data to be committed: The participant still has locks on the items the transaction is executed on, so it can just rewrite the data (which will be available on the channel).
- The participant fails in the abort or commit states: The transaction is complete, so nothing needs to be done.
We see that with an asynchronous reliable store-and-forward channel we can, given enough time, recover from any site failure without using a termination protocol.
'programming > MSSQL' 카테고리의 다른 글
| [펌]Concurrency control mechanism (0) | 2005.03.29 |
|---|---|
| QL Server Professional: T-SQL Coding Standards (0) | 2005.03.01 |
| How to configure RPC dynamic port allocation to work with firewalls (0) | 2005.02.25 |